


小米突破性开源 Xiaomi-MiMo-Audio,开启语音大模型新纪元



本文由广东鲸弘科技有限公司提供惠州小程序开发 / 网站建设专业分享。
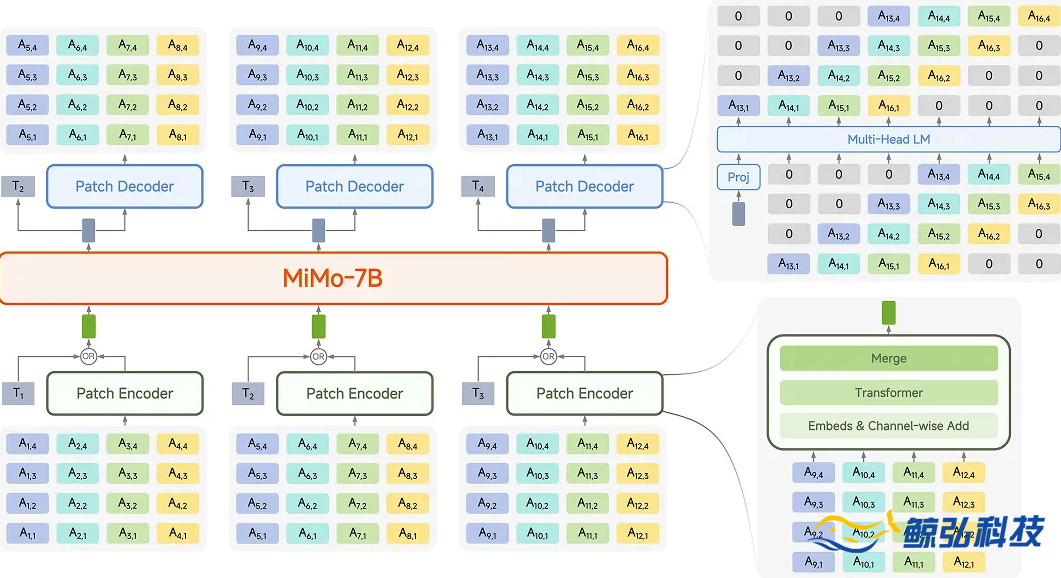
在人工智能领域,语言大模型的发展早已迈入通用人工智能(AGI)的新阶段。五年前,GPT-3 凭借自回归语言模型与大规模无标注数据训练,成功解锁强大的 In-Context Learning(ICL)能力,仅需少样本就能迁移到新任务,为语言领域的 AGI 发展奠定基础。然而,语音领域却长期受困于一大瓶颈 —— 现有模型对大规模标注数据依赖度极高,难以像语言模型那样快速适应新任务,距离类人智能还有不小差距。
就在行业对语音领域的突破翘首以盼时,小米带来了重磅消息:正式开源首个原生端到端语音大模型 ——Xiaomi-MiMo-Audio。这款模型依托创新预训练架构,经过上亿小时数据训练,一举打破语音领域的发展僵局,首次在该领域实现基于 ICL 的少样本泛化能力,更在预训练阶段观察到显著的 “涌现” 行为,为语音领域的技术革新注入强劲动力。
不仅如此,通过后训练优化,Xiaomi-MiMo-Audio 在跨模态对齐能力上实现全面提升,无论是智商、情商,还是表现力与安全性,都达到新高度。这直接体现在语音对话中,其在自然度、情感表达以及交互适配方面,呈现出极高的拟人化水准,让语音交互体验更贴近人与人之间的真实沟通。
性能亮眼:开源模型媲美闭源强者
Xiaomi-MiMo-Audio 的卓越性能,源于创新模型结构、上亿小时数据预训练与轻量后训练的完美结合,在多项测试中展现出惊人实力:
在通用语音理解、语音对话等主流标准评测基准中,MiMo-Audio 大幅超越同参数量级的开源模型,以 70 亿参数规模拿下该量级最佳性能,成为开源语音模型中的佼佼者。
音频理解基准 MMAU 的标准测试集上,它展现出超越 Google 闭源语音模型 Gemini-2.5-Flash 的实力,打破闭源模型在该领域的优势局面。
面对音频复杂推理场景,在 Big Bench Audio S2T 任务中,MiMo-Audio 同样不甘示弱,成功超越 OpenAI 闭源语音模型 GPT-4o-Audio-Preview,证明开源模型在复杂任务处理上的巨大潜力。
多重创新:多个 “首次” 引领行业变革
Xiaomi-MiMo-Audio 之所以能实现性能突破,关键在于其一系列开创性的技术贡献,多个 “首次” 推动语音领域进入新发展阶段:
首次验证语音无损压缩预训练规模扩展至 1 亿小时的价值 —— 当训练数据达到这一量级,模型 “涌现” 出跨任务泛化能力,具体表现为出色的 Few-Shot Learning(少样本学习)能力,这一突破被业内视为语音领域的 “GPT-3 时刻”,标志着语音大模型发展进入全新阶段。
首次明确语音生成式预训练的目标与定义,并开源一套完整的语音预训练方案。该方案涵盖无损压缩的 Tokenizer(令牌生成器)、全新模型结构、科学的训练方法以及完善的评测体系,为语音领域的研究提供了标准化、可复用的基础框架,开启语音领域的 “LLaMA 时刻”,推动行业研究加速前行。
首次将 “Thinking(思考)” 机制同时融入语音理解与语音生成过程,推出支持混合思考模式的开源模型。这一创新让模型在处理语音任务时,能像人类一样进行逻辑思考,进一步提升任务处理的准确性与合理性。
全面开源:助力语音领域协同发展
小米秉持简单、彻底、直接的开源理念,将 Xiaomi-MiMo-Audio 的核心资源全面开放,旨在为语音研究领域搭建协作平台,加速技术创新与应用落地:
核心模型开源
预训练模型 MiMo-Audio-7B-Base:作为目前开源领域首个具备语音续写能力的语音模型,为开发者提供了语音生成类任务研究的重要基础,模型获取地址:https://huggingface.co/XiaomiMiMo/MiMo-Audio-7B-Base。
指令微调模型 MiMo-Audio-7B-Instruct:经过轻量级 SFT(指令微调)优化,成为 70 亿参数规模下性能最强的语音理解与生成模型。该模型支持通过 prompt(提示词)灵活切换 non-thinking(无思考)、thinking(思考)两种模式,且强化学习(RL)起点高、潜力大,可作为语音 RL 与 Agentic 训练研究的全新基座模型,获取地址:https://huggingface.co/XiaomiMiMo/MiMo-Audio-7B-Instruct。
Tokenizer 开源
小米开源的 MiMo-Audio Tokenizer 模型,采用 Transformer 架构,参数量达 12 亿,在效率与性能之间实现完美平衡。该模型基于超过千万小时语音数据从头训练,同时支持音频重建与音频转文本(A2T)任务,为语音数据处理提供关键工具。其高效推理代码已同步开源,地址:https://github.com/XiaomiMiMo/MiMo-Audio-Tokenizer。
技术报告与评估框架开源
技术报告:详细披露 MiMo-Audio 模型的架构设计、训练流程、性能测试等核心细节,为研究者深入了解模型提供全面参考,报告地址:https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf。
评估框架:提供一套覆盖模型全生命周期的评估体系,包含预训练 ICL 测评、后训练评估等功能,支持 10 余种测评任务,为语音模型的性能验证与优化提供标准化工具,框架开源地址:https://github.com/XiaomiMiMo/MiMo-Audio-Eval。
Xiaomi-MiMo-Audio 的开源,不仅打破了语音大模型发展的技术瓶颈,更以全面的资源开放为行业注入新活力。相信在这一模型的推动下,语音领域将迎来更多技术突破,加速语音 AI 在智能终端、智能家居、人机交互等场景的深度应用,为用户带来更智能、更自然的语音体验。




-
腾讯混元 HunyuanVideo-Foley 开源:AI 视频音效生成进入电影级时代,多场景效率革命来袭
 2025-08-29
123
2025-08-29
123 -
今日 AI 快讯 | 2026.4.11 大模型 / 算力 / 应用全领域速览
2026-04-11
109
-
企业 AI 落地参考:2026 年 4 月 5 日 AI 应用案例与趋势
2026-04-05
209
-
美团 AI 生活小秘书 “小美”:解锁便捷生活新方式
2025-09-13
292
-
CombatVLA – 淘天集团推出的3D动作游戏专用VLA模型
2025-08-20
172
-
AI 算法基础:企业非技术人员也能看懂的科普
2026-03-20
62
-
广东 AI 技术服务:企业数字化转型专业解决方案
2026-03-29
55
-
Apertus:瑞士开源大模型的破局之作,以多语言与透明性重塑 AI 生态
2025-09-06
130
-
马斯克携 Grokipedia 宣战维基百科:AI 驱动的知识平台能否重塑信息格局?
2025-10-01
159
-
AI 在行业中的实际应用:提升效率与体验的案例
2026-03-24
78





 咨询热线:
咨询热线:







 联系电话
联系电话 联系邮箱
联系邮箱 联系QQ
联系QQ 方案获取
方案获取
