


杭州六小龙再放大招!SpatialGen 开源:一句话生成可漫游 3D 空间,SpatialLM 1.5 将解锁机器人训练新场景



本文由广东鲸弘科技有限公司提供惠州小程序开发 / 网站建设专业分享。
在今日下午的群核科技首届技术开放日上,群核科技宣布开源 3D 场景生成模型 SpatialGen ,即将开源空间语言模型 SpatialLM 1.5 ,并首次分享基于 SpatialGen 探索的 AI 视频生成解决方案 ,旨在解决时空一致性难题。而 SpatialLM 1.5 不仅能理解文本指令,还能输出包含空间结构、物体关系、物理参数的 “空间语言”,可被用于具身智能机器人的虚拟训练,解决数据难题。SpatialGen 已在 Hugging Face、GitHub、魔搭开源。
群核科技 AI 产品总监龙天泽透露,群核科技正在做一个 “SpatialGen + AI 视频创作” 的内部保密项目,代号 X。其基于 3D 技术的 AI 视频生成产品计划在今年发布 ,可能成为 “全球首款深度融合 3D 能力的 AI 视频生成 Agent ”。这个视频呈现出几个特点:在有超过十个分镜的情况下保持精准的一致性,动作没有崩坏,能够精准卡点,在复杂运镜下画面内容依然合理,并实现内容可控性。
当前空间大模型仍面临三大技术挑战:室内空间数据获取比室外空间数据更困难、空间结构复杂度高、具身智能等场景中的交互需求更高 。截至 2025 年 6 月 30 日,群核科技拥有包含超过 4.41 亿个 3D 模型及超过 5 亿个结构化 3D 空间场景。黄晓煌说,“相比大语言模型,当前空间大模型还处于初级阶段。据介绍,群核空间大模型是业界首个专注于 3D 室内场景认知和生成的空间大模型 ,基于大规模、高质量的 3D 场景数据训练而成。群核科技首席科学家周子寒对此做了解释。视频生成模型、世界模型面临空间一致性、视角灵活度 两大挑战。World Labs、混元 3D 世界模型等 3D 场景类模型,可以保证视角一致性,但在视角灵活性受限,而且模型通常基于游戏数据场景训练,难以很好地实现真实感。
与世界模型相比,群核科技空间大模型有三大核心优势:真实感全息漫游、结构化可交互、复杂室内空间场景生成能力 。
真实感全息漫游场景:由于开源 3D 场景数据稀缺,已有的工作在算法选择上受限,一般通过蒸馏 2D 生成模型,导致结果视觉真实性不足;基于群核数据集,我们设计并训练面向场景的多视角扩散模型以生成高质量图像。
结构化可交互:可生成包含空间结构、空间关系等丰富物理参数信息的场景语言,相较于传统大语言模型可精准解析空间布局与物体关系,支持参数化场景生成和编辑,为机器人的路径规划等任务提供必要场景可交互信息。
复杂室内空间处理能力:作为全球最大的空间设计平台,沉淀了数以亿计的 3D 模型和空间场景资产,其 InteriorNet 也成为了当时全球最大的室内空间深度学习数据集,群核在室内空间数据的优势使空间大模型可处理更复杂的场内场景生成和交互。
得益于上述优势,群核空间大模型可处理更复杂的场内场景生成和交互,并能精准解析空间布局与物体关系,支持参数化场景生成和编辑,为机器人的路径规划等任务提供必要场景可交互信息。目前,该模型已开源两大核心子模型:空间语言模型 SpatialLM (结构化可交互)和空间生成模型 SpatialGen(真实感全息漫游)。
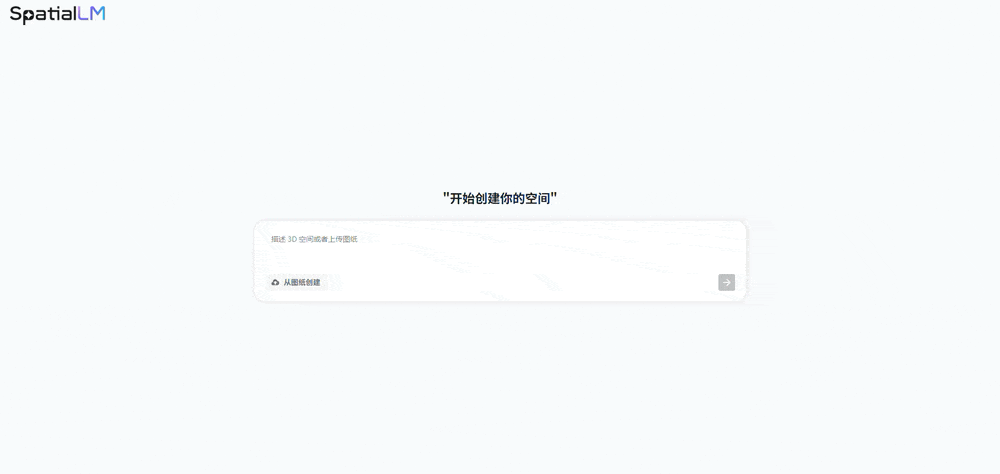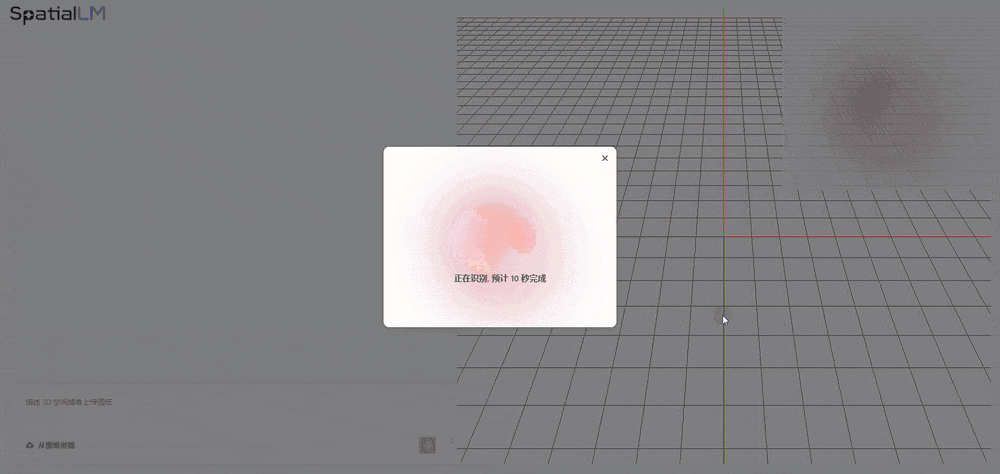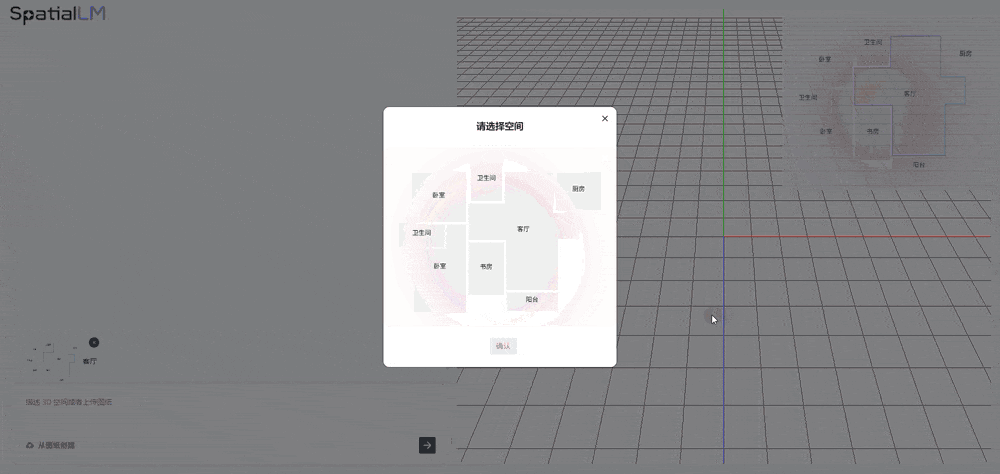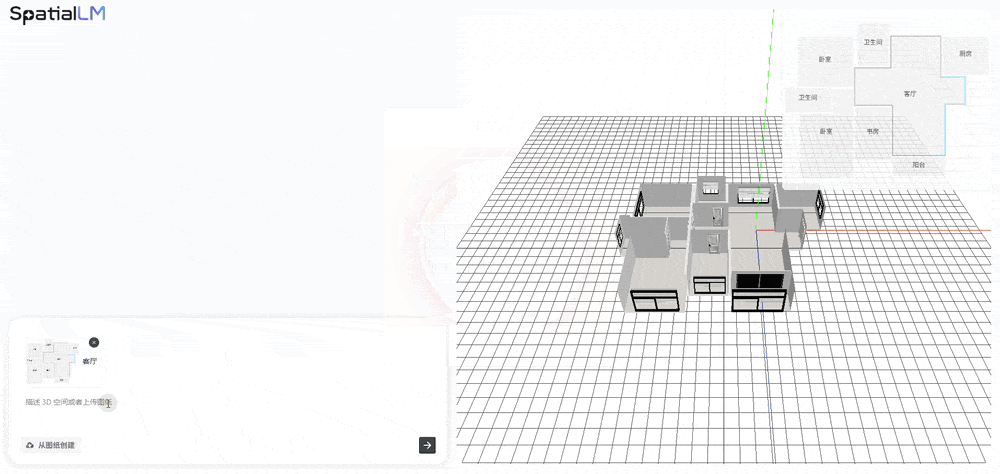
今日发布的 SpatialLM 1.5,是一款基于大语言模型训练的空间语言模型,支持用户通过对话交互系统 SpatialLM-Chat 进行可交互场景的端到端生成。SpatialLM 1.5 不仅能理解文本指令,还能输出包含空间结构、物体关系、物理参数的 “空间语言”。例如,用户输入简单文本描述,SpatialLM 1.5 就能生成结构化场景脚本,智能匹配家具模型并完成布局,还支持通过自然语言对现有场景进行问答或编辑。其核心技术路径是在 GPT 等大语言模型(LLM)基础上,通过融合 3D 空间描述语言能力 构建增强型模型,使其既能理解自然语言,又能以类编程语言(如 Python)的结构化方式对室内场景进行理解、推理和编辑。
据周子寒分享,SpatialLM 1.5 的底模是通义千问,然后增加空间数据做训练。由于 SpatialLM 1.5 生成的场景富含物理正确的结构化信息,且能快速批量输出大量符合要求的多样化场景,可用于机器人路径规划、避障训练、任务执行 等场景,有效解决当前机器人训练 “缺数据” 的难题 。借助 SpatialLM 的空间参数化生成能力,可以高效创建具备物理准确性的具身智能机器人训练场景:首先基于自然语言描述生成结构化空间方案,继而自动匹配素材库构建三维环境,最终输出可供机器人进行路径仿真的可交互场景。现场,周子寒演示了机器人养老场景的应用,当输入 “去客厅餐桌拿药” 这一指令后,该模型不仅理解了相关的物体对象,还调用工具自动规划出最优行动路径,展示了机器人在复杂家庭环境中执行任务的潜力。
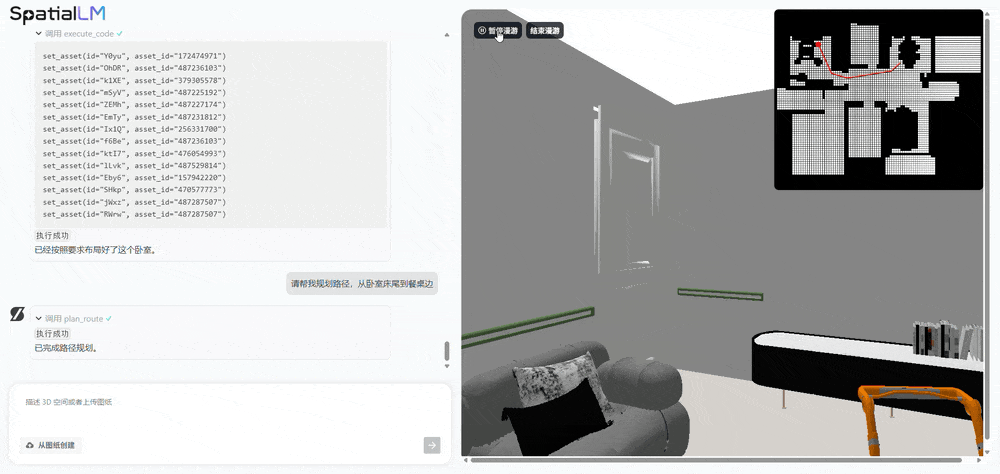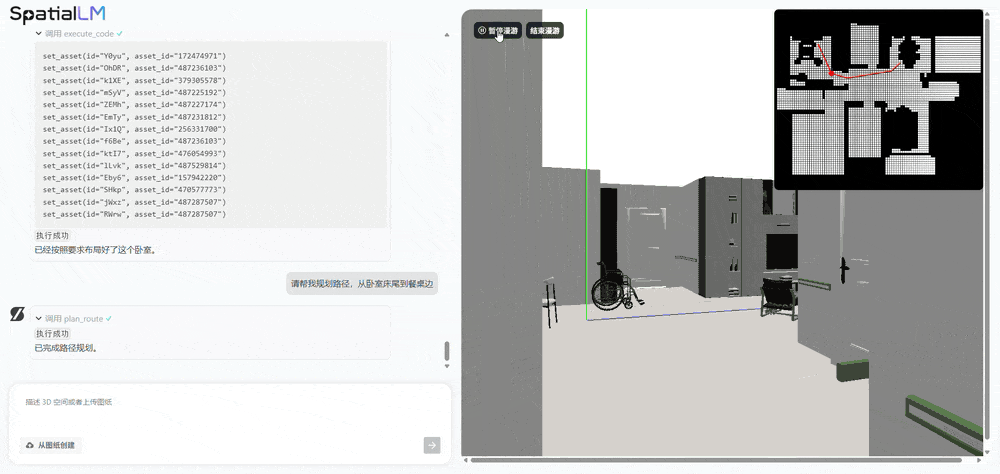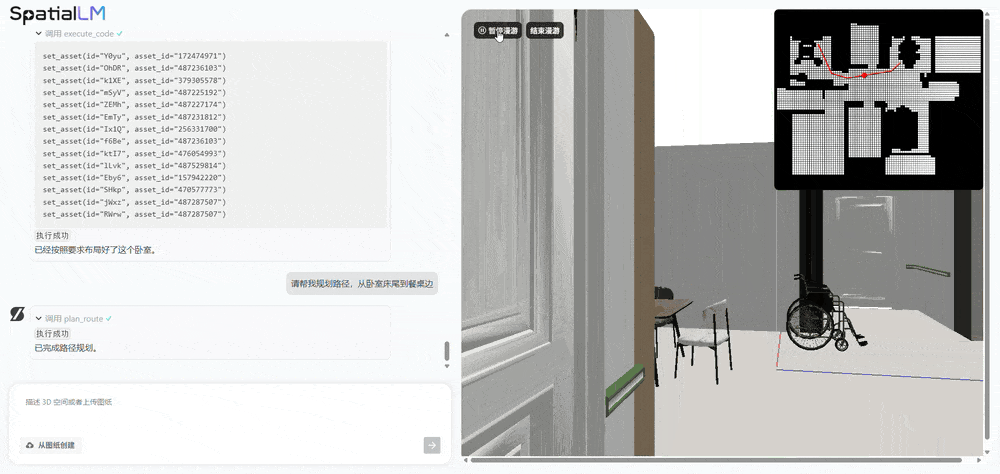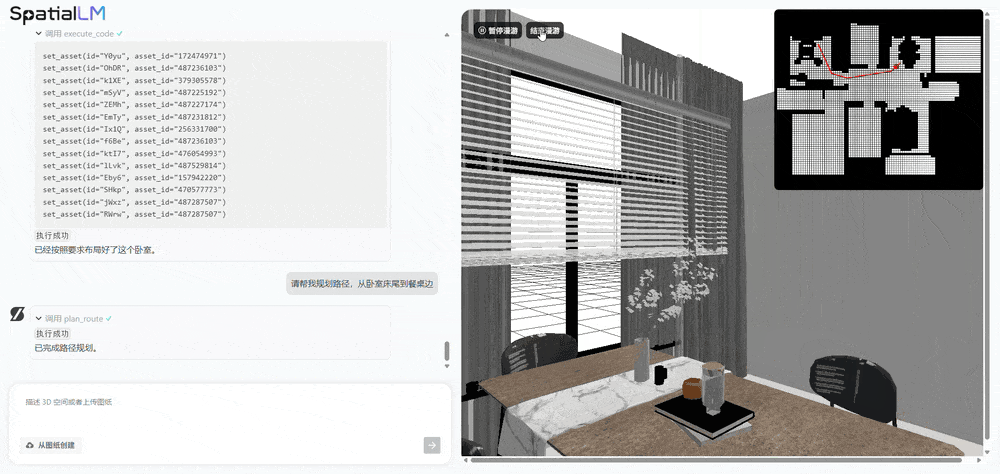
多视角图像生成模型 SpatialGen:搞定时空一致性,打造可自由漫游的 3D 世界
SpatialLM 解决的是 “理解与交互” 问题,SpatialGen 则专注于 “生成与呈现”。SpatialGen 是一款基于扩散模型架构的多视角图像生成模型,可根据文字描述、参考图像和 3D 空间布局,生成具有时空一致性的多视角图像,并支持进一步得到 3D 高斯(3DGS)场景并渲染漫游视频。该模型依托群核科技海量室内 3D 场景数据 与多视角扩散模型技术,其生成的多视角图像能确保同一物体在不同镜头下始终保持准确的空间属性和物理关系。基于 SpatialGen 生成的 3D 高斯场景和真实感全息漫游视频,用户可以如同在真实空间中一样,自由穿梭于生成的场景内,获得沉浸式的体验。对比之下,其他开源视频模型会在移动过程中生成一些幻觉。
SpatialGen 有三大技术优势:
大规模、高质量训练数据集:由于开源 3D 场景数据稀缺,已有的工作在算法选择上受限,一般通过蒸馏 2D 生成模型,导致结果视觉真实性不足;基于群核数据集,群核科技设计并训练面向场景的多视角扩散模型,以生成高质量图像。
灵活视角选择:已有方法基于全景图生成还原,3D 场景完整性较差;或基于视频底模,无法支持相机运动控制等。SpatialGen 在这一方面具有优势。
参数化布局可控生成:基于参数化布局生成,未来可支持更丰富的结构化场景信息控制。
其工作流是:给定一个 3D 空间布局,首先在空间中采样多个相机视角,然后基于每个视角将 3D 布局转为对应 2D 语义图和深度图。将它与文字、参考图一起,通过一个多视角扩散模型生成每个视角对应的 RGB 图,以及语义图和深度图(户型、家具物体等在相机视角的投影)。最后,通过重建算法得到场景的 3DGS。
群核科技发现,基于 SpatialGen 的能力,能够快速补足现有视频生成能力无法解决空间一致性的问题。例如一些视频生成类模型,物体在形状和空间关系,在多帧画面中无法保持稳定和连贯。而能用于商业化短剧创作的 AIGC,不仅要求每一帧画面 “看起来合理”,更要求整个视频序列在空间中像真实世界一样 “合理存在”。“这可能是全球首款深度融合 3D 能力的 AI 视频生成 Agent 。” 该产品通过构建 3D 渲染与视频增强一体化的生成管线,有望显著弥补当前 AIGC 视频生成中时空一致性不足的问题。空间一致性是指在生成视频的过程中,物体的形状和空间关系在多帧画面中保持稳定和连贯。据龙天泽分享,空间一致性对人类很基本,但对 AI 很难。




-
定制化 AI 解决方案:为企业打造专属智能系统
 2026-03-27
75
2026-03-27
75 -
惠州企业 AI 参考 | 2026.4.8 AI 技术落地最新案例
2026-04-08
107
-
Kimi K2 模型更新,带来更强的代码能力、更快的 API
2025-09-07
212
-
腾讯混元 HunyuanVideo-Foley 开源:AI 视频音效生成进入电影级时代,多场景效率革命来袭
2025-08-29
130
-
企业 AI 落地难?从技术到应用的完整解决方案
2026-03-18
62
-
2026 AI 四大关键词:协作、落地、合规、融合,行业变革底层逻辑解析
2026-01-04
261
-
重磅连发:Meta 推出 SAM 3D+SAM 3,计算机视觉迈入 “精准交互 + 实景重建” 新时代
2025-11-21
172
-
人工智能算力是什么?对企业业务有哪些影响?
2026-03-24
69
-
2026年4.14-4.20 AI大事件汇总:模型迭代+产业落地+政策扶持,AI行业迎爆发期
2026-04-20
188
-
AI 科技日报 | 2026 年 4 月 1 日 行业热点与技术突破盘点
2026-04-01
217





 咨询热线:
咨询热线:







 联系电话
联系电话 联系邮箱
联系邮箱 联系QQ
联系QQ 方案获取
方案获取
